import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# headr=None : 데이터프레임에서 컬럼명을 설정해주는 함수(None : 인덱스 번호로 출력됨)
data = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/빅데이터 13차(딥러닝)/data/ThoraricSurgery.csv", header=None)
data
# 17번 인덱스 행이 환자의 생존여부를 표시
# 인덱싱으로 문제(17번을 제외한 나머지 열), 정답(17번 인덱스 열)을 설정해보세요
X = data.iloc[:,:-1] # [행의범위, 열의범위]
y = data.iloc[:, -1]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
random_state=10
)
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# 신경망 구조 설계
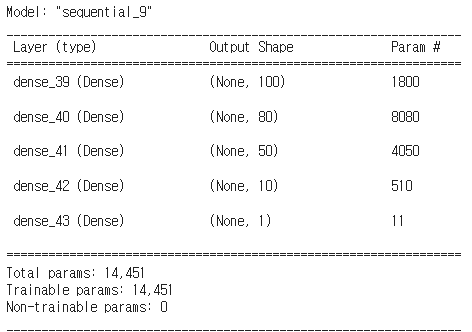
model = Sequential()
# input_dim : 입력되는 데이터의 특성 개수를 설정
# activation : 활성화 함수를 설정(들어온 자극(데이터)에 대한 응답여부(예측결과)를 결정하는 함수)
# 입력층(input_dim) + 중간 1개층(Dense)
model.add(Dense(100, input_dim=17, activation='relu'))
# 중간층
model.add(Dense(80, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(10, activation='relu'))
# 출력층
model.add(Dense(1, activation='sigmoid'))
model.summary()
# 학습 및 평가방법 설정
# binary_crossentropy : 2진분류에 사용하는 손실함수
# -> 오차의 평균을 구하는 것은 mse와 같지만 0~1사이의 값으로 반환한 후에 평균오차를 구함(그래야 0또는1로 분류하기 편하니까!)
model.compile(loss='binary_crossentropy',
optimizer='Adam', # 최적화함수 : 확률적 경사하강법
metrics=['acc'] # metrics : 평가방법을 설정(분류문제이기 때문에 정확도를 넣어줌)
)
# 학습
h = model.fit(X_train, y_train, epochs=100)
plt.figure(figsize=(15,5))
plt.plot(h.history['acc'], label='acc')
plt.legend()
plt.show